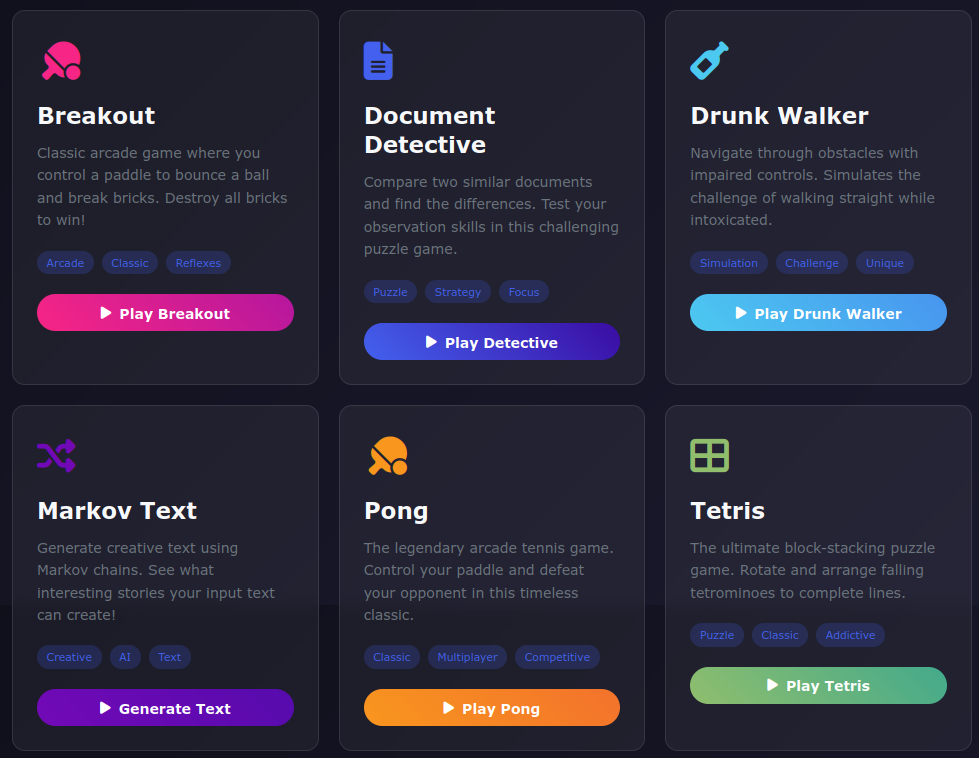
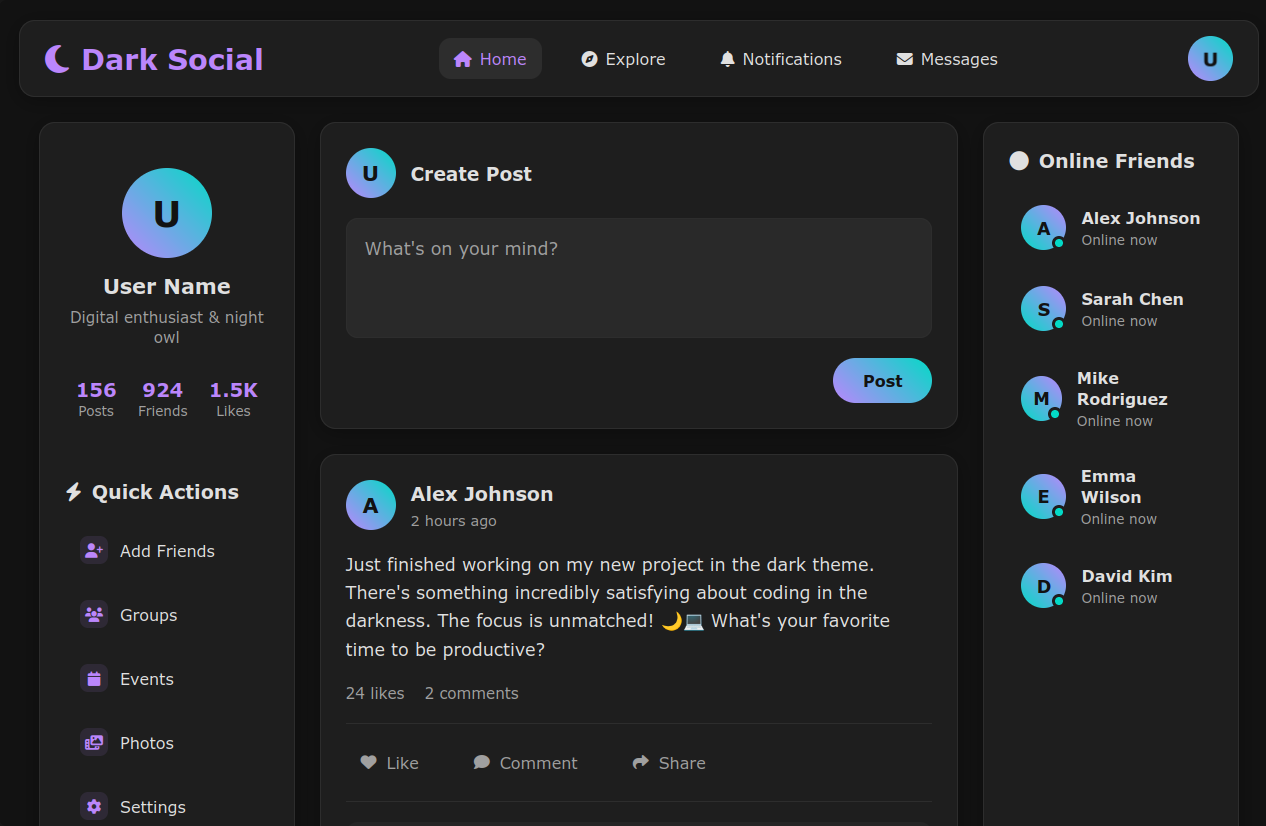
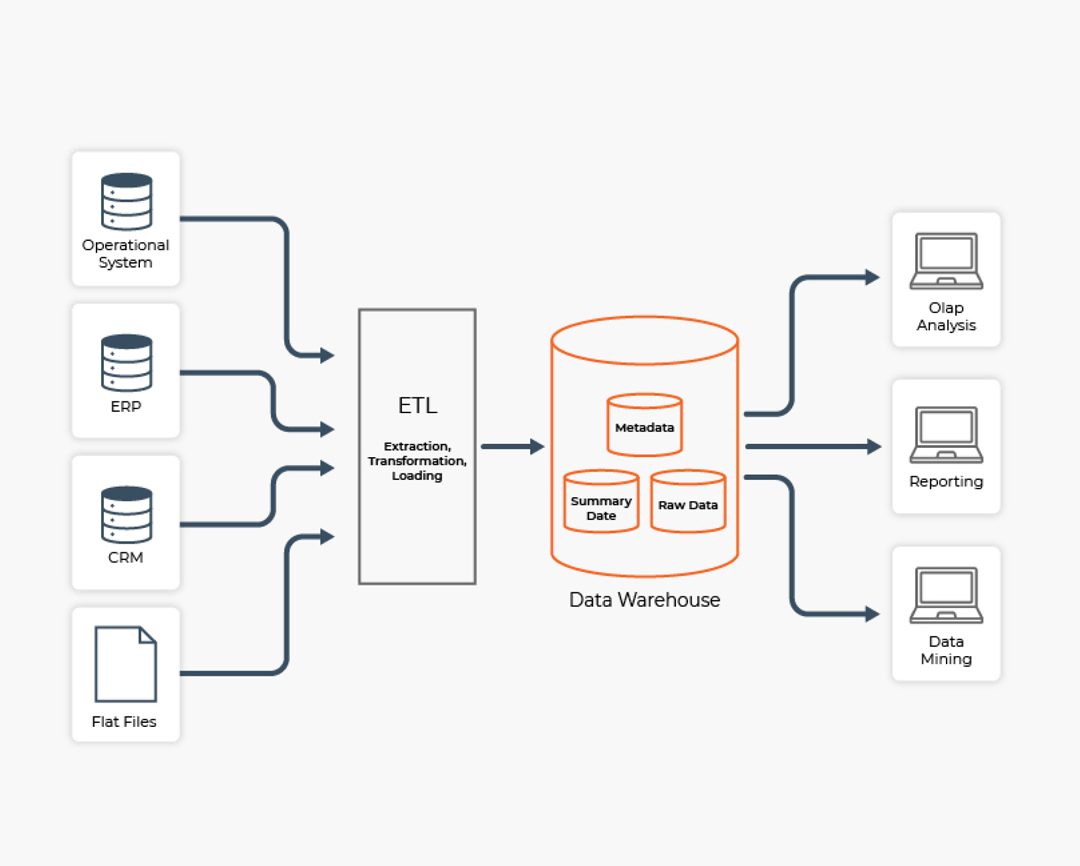
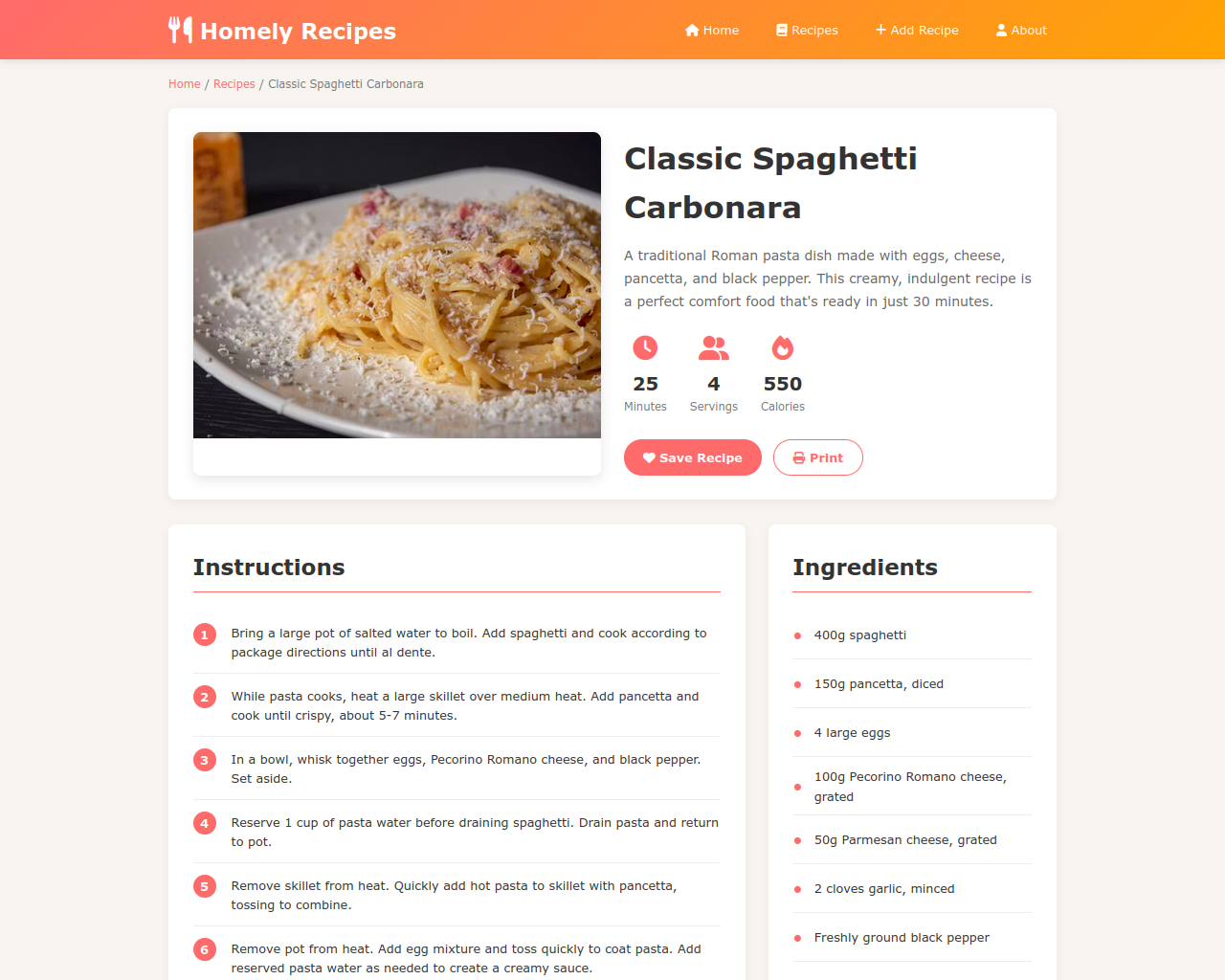
Hello I'm
Shubham
I’m a data scientist and analyst.
I turn complex datasets into actionable business insights.
- shubhamdparulekar1@gmail.com
- Urbana-Champaign, Illinois, United States